Backward warping/skinning has been used to model non-rigid implicit shapes. It maps poitns from deformed space to canonical space. The backward skinning weights field is defined in deformed space, therefore it's pose-dependent and does not generalize to unseen poses.
Backward vs. Forward
We propose to use Forward skinning for animating implicit shapes. It maps points from canonical space to deformed space. The forward skinning weights field is defined in the canonical space. Thus, forward skinning naturally generalizes to unseen poses.
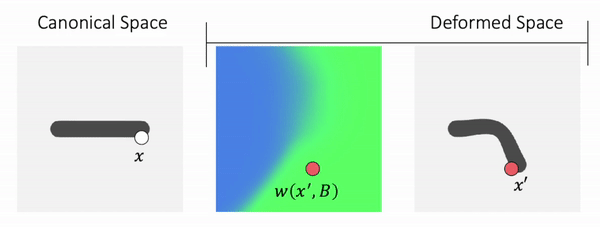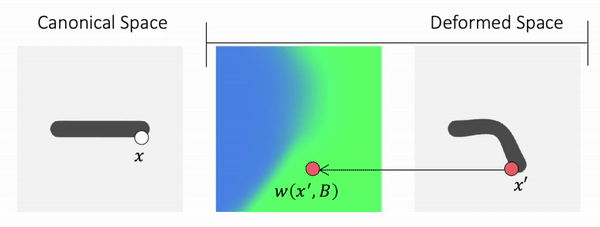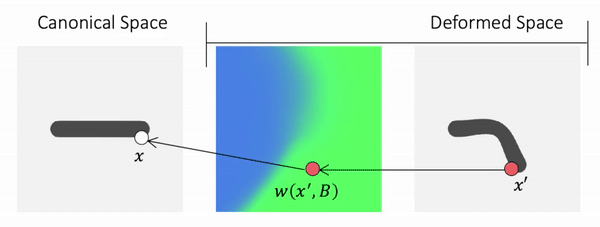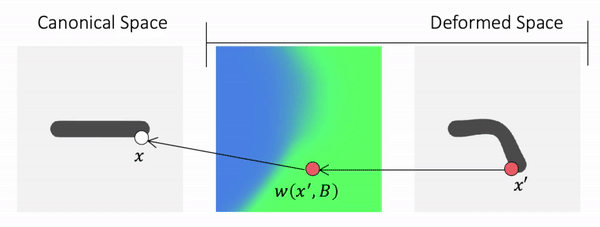
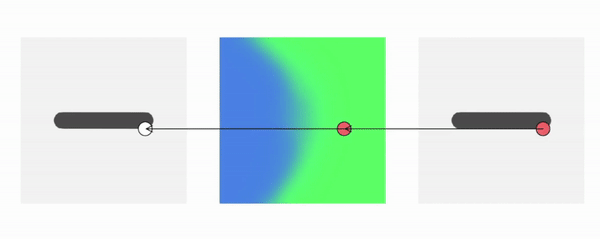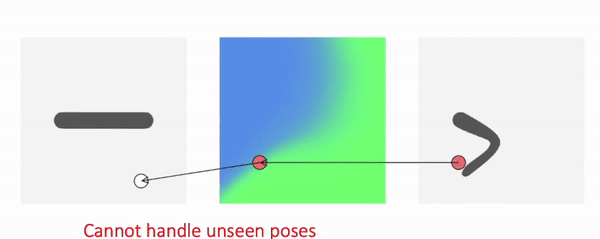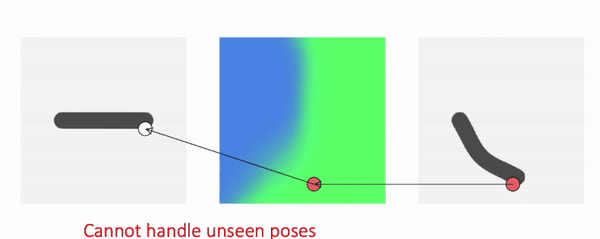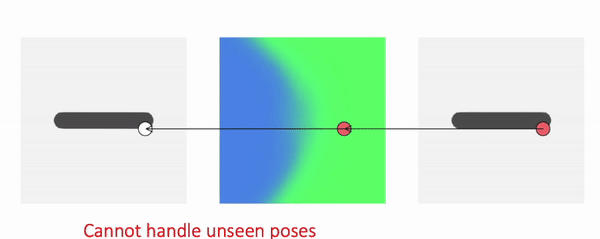
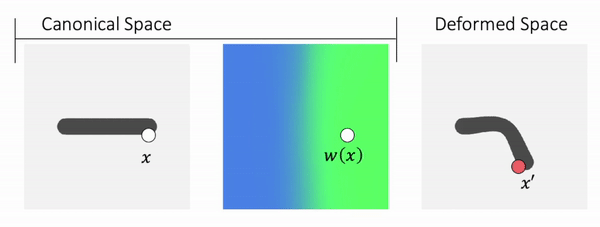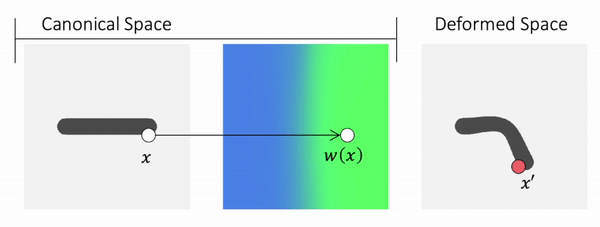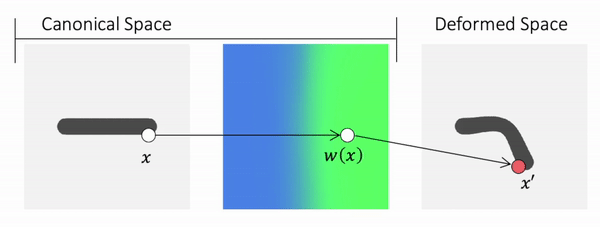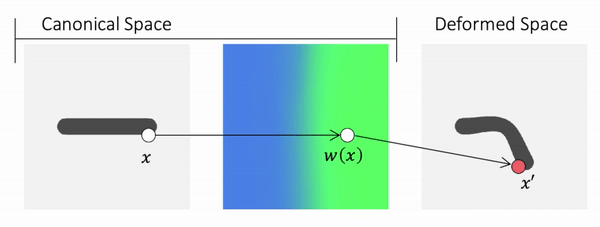
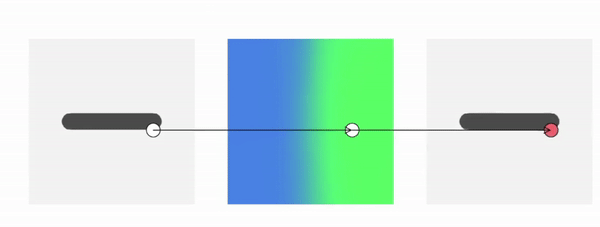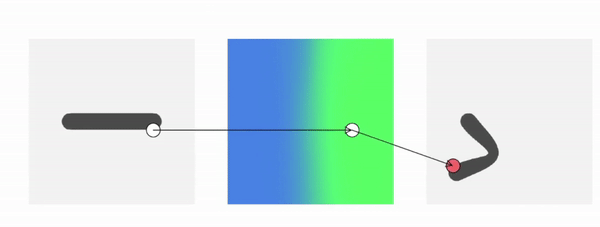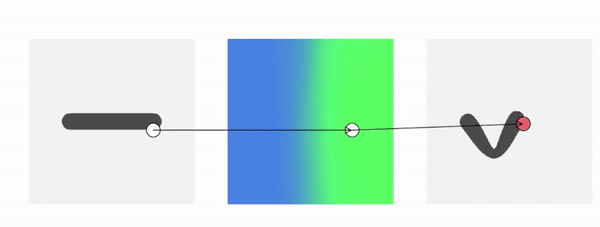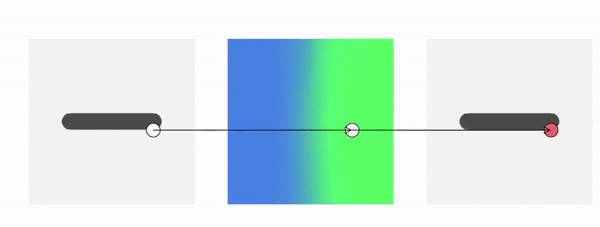
Method Overview
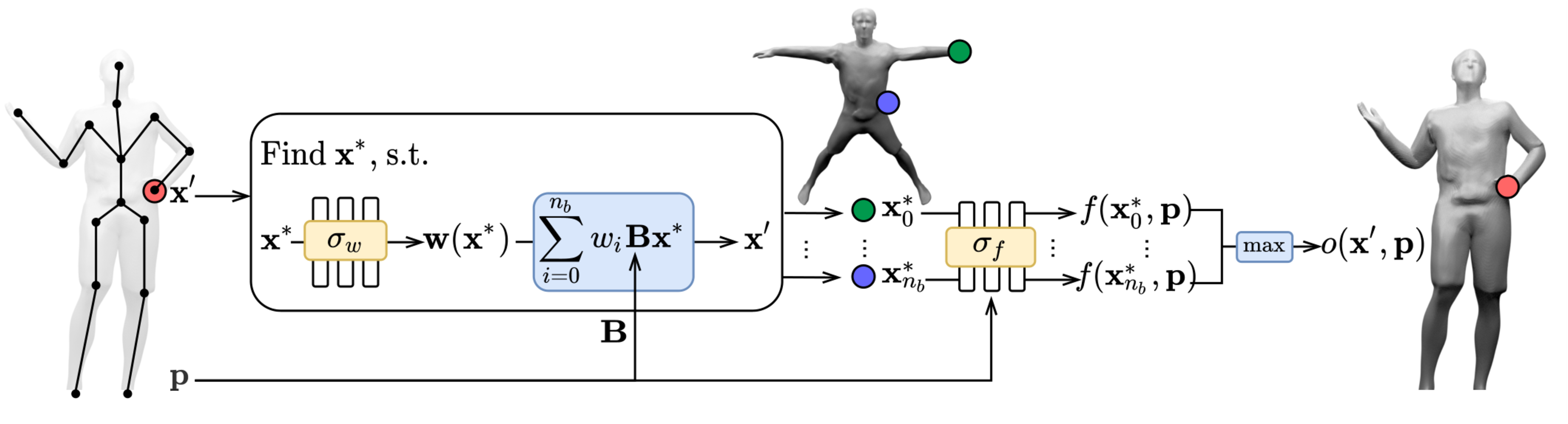
To genreate deformed shape or to train with deformed observations, we need to determine the canonical correspondence of any given deformed point. This is trivial for backward skinning, but not straightforward for forward skinning. The core of our method is to find the canonical correspondence of any deformed point using forward skinning weights. We use iterative root finding algorithm with multiple initializations to numerically find all corrpondences, and then aggregate their occupancy probabilities using max operator as the occupancy of the deformed point. Finnally, we derive analytical gradients using the implicit differentiation theorem, so that the whole pipeline is end-to-end differentiable and thus can be trained with deformed observations directly.
Comparison
We train our method using meshes in various poses and ask the model to generate novel poses during inference time:
As shown, our method generalizes to these challenging and unseen poses. In comparison, backward skinning produces distorted shapes for unseen poses. The other baseline, NASA, models human body as a composition of multiple parts and suffers from discontinuous artifacts at joints.
BibTeX
@inproceedings{chen2021snarf,
title={SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes},
author={Chen, Xu and Zheng, Yufeng and Black, Michael J and Hilliges, Otmar and Geiger, Andreas},
booktitle={International Conference on Computer Vision (ICCV)},
year={2021}
}